机器学习算法加速库
鲲鹏基于算法原理和芯片特征,针对Spark开源版本机器学习MLlib算法库进行深入优化,实现相比Spark开源版本对应算法库性能提高50%。
机器学习算法加速库提供以下算法优化,后续版本会持续更新增加算法。
分类回归(Random Forest、GBDT、SVM、Logistic Regression、Linear Regression、Decision Tree、XGBoost、KNN)、聚类(K-means、DBSCAN、LDA)、特征工程(PCA、SPCA、SVD、Pearson、Covariance、Spearman、IDF、DTB、Word2Vec)、模式挖掘(ALS、PrefixSpan、SimRank)。
算法的常用应用场景如表1所示。
|
算法名称 |
运营商 |
金融 |
交通 |
|---|---|---|---|
|
Random Forest |
|
|
|
|
GBDT |
|
|
|
|
SVM |
|
|
|
|
Logistic Regression |
|
|
|
|
Linear Regression |
|
|
|
|
Decision Tree |
|
|
|
|
XGBoost |
|
|
|
|
KNN |
|
|
|
|
K-means |
|
|
|
|
DBSCAN |
|
|
|
|
LDA |
|
|
|
|
PCA |
|
|
|
|
SVD |
|
|
|
|
Pearson |
|
|
|
|
Covariance |
|
|
|
|
Spearman |
|
|
|
|
DTB |
|
|
|
|
Word2Vec |
|
|
|
|
ALS |
|
|
|
|
PrefixSpan |
|
|
|
大数据算法加速库提供与Spark开源版本MLlib相同的接口,保证客户的应用程序无需任何修改即可使用算法库。
大数据算法加速库具体部署操作参见《机器学习算法加速库 特性指南》。
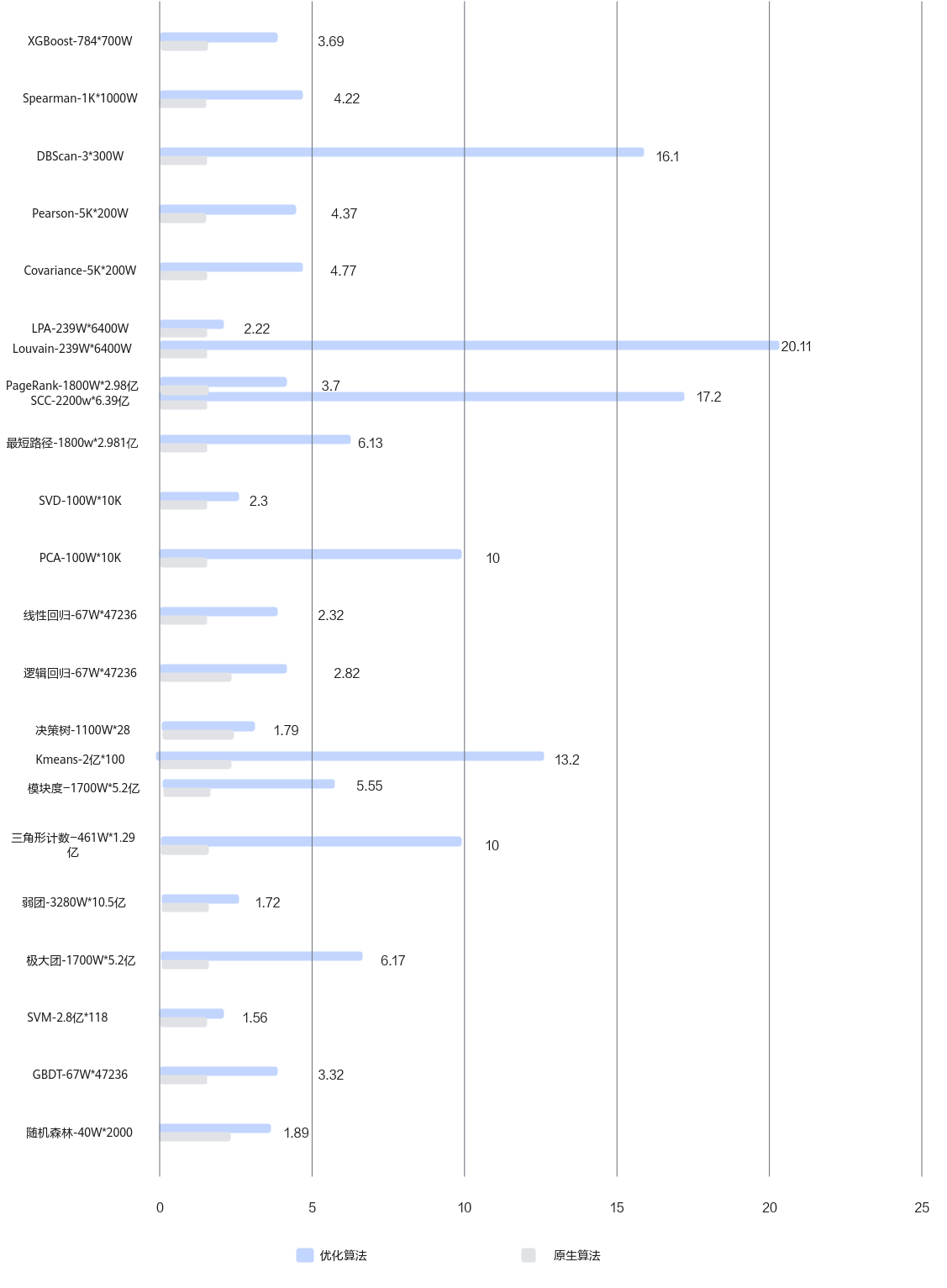
基于网络公开的数据集,鲲鹏920 5250处理器运行机器学习算法加速库,相比友商运行Spark开源版本算法,计算性能提升50%以上。
图1 算法库性能对比
父主题: 方案特性