中心性分析
场景介绍
中心性分析类算法旨在分析图上各个结点重要性,例如, Twitter用户被许多其他用户关注,则该用户的排名会很高。
算法原理
- K-Core算法
K-Core(K-Core Decomposition,k核算法)对用户输入的图数据,精确求解图中各个结点coreness值。其中coreness值的定义如下:一个顶点属于k-core subgraph,但不属于(k+1)-core subgraph,则这个顶点的core number = k。k-core subgraph的定义如下:图G中的极大子图Gk,Gk中的所有顶点的度deg(v) ≥ k。
- PageRank算法
PageRank,网页排名算法是Google公司所使用的对其搜索引擎搜索结果中的网页进行排名的一种算法,也是图计算及推荐领域的基础算法。PageRank本质上是一种以网页之间的超链接个数和质量作为主要因素粗略地分析网页的重要性的算法。其基本假设是:更重要的页面往往更多地被其他页面引用(或称其他页面中会更多地加入通向该页面的超链接)。
- TrustRank(信任指数)
TrustRank(信任指数)算法,是PageRank算法的变种,基于以下理论假设:优质网站很少会链接到垃圾网站,反之则不成立。选定高质量种子结点,那么由“种子”结点指向的结点也可能是高质量结点,即其TrustRank也高,与“种子”结点的链接越远,结点的TrustRank越低。
- Personal PageRank(个性化网页排名)
Personal PageRank算法,是图计算及推荐领域的基础算法,是指给定一份关系型数据和源结点,计算该结点对网络中其他结点的影响性。
- Closeness算法
Closeness,紧密中心性算法计算图中紧密中心性值最大的K个结点,支持有向图(含有/无权图,有权图要求输入边权值大于0)。紧密中心性计算的目的是衡量图中每个结点的与其它结点之间的接近程度,结点与其它结点的平均距离越短,则结点的紧密中心性值越大,结点在图中的重要性也就越高。紧密中心性的计算基于图中每个结点到其它所有结点的平均距离计算,然后得出每个结点的紧密中心性的值,最后选取图中紧密中心性值最大的K个结点,输出这K个结点的编号和紧密中心性值。
- Betweenness(介数中心性)
Betweenness(介数中心性)算法计算图中介数中心性值最大的K个结点,是网络中心性重要的度量参数之一,同时也是图计算领域的基础算法。介数中心性算法的目的是衡量图中每一个结点与其它结点之间的互动程度,经过结点的最短路径数越多,该结点的介数中心性值越大,结点在图中的重要性也就越高。结点的介数中心性值是基于图中最短路径经过该结点的次数计算,最后选取图中介数中心性值最大的K个结点,输出这K个结点的编号和介数中心性值。
- Weighted PageRank算法
Weighted PageRank,有权网页排名算法,经典PageRank算法主要面向无权场景,在实际业务场景中,网络往往带有权重,有权网页排名算法基于经典PageRank算法改进,是一种利用网页之间链接权重和质量作为主要因素分析网页重要性的算法。
- Incremental PageRank算法
Incremental PageRank,增量PageRank是基于PageRank的增量式算法,适用于图计算及推荐领域的增量场景。对于不断膨胀的网络,网络增量部分相比存量图数量是很小的,Incremental PageRank算法可以重复利用存量结果,避免将整个网络进行重新计算,保证一定精度的情况下,降低计算量,提升计算性能。
- Trillion PageRank算法
Trillion PageRank,万亿PageRank。PageRank算法,是Google公司所使用的对其搜索引擎搜索结果中的网页进行排名的一种算法,也是图计算及推荐领域的基础算法。针对大规模数据场景,原始数据以邻居列表集合存储,符合一个网页链接多个网页的逻辑关系,利用PageRank算法可以估计网页的重要程度,即更重要的网页往往被更多的网页引用。
编程实例
本示例以K-Core算法来介绍编程示例。
run API
- API
def run(edgeList: RDD[(Long, Long)]): RDD[(Long, Int)]
- 功能描述
计算图中所有结点的coreness值。本算法的输入为无权无向图,输入仅需输入单向边(1L, 2L),无需包含(2L, 1L)。
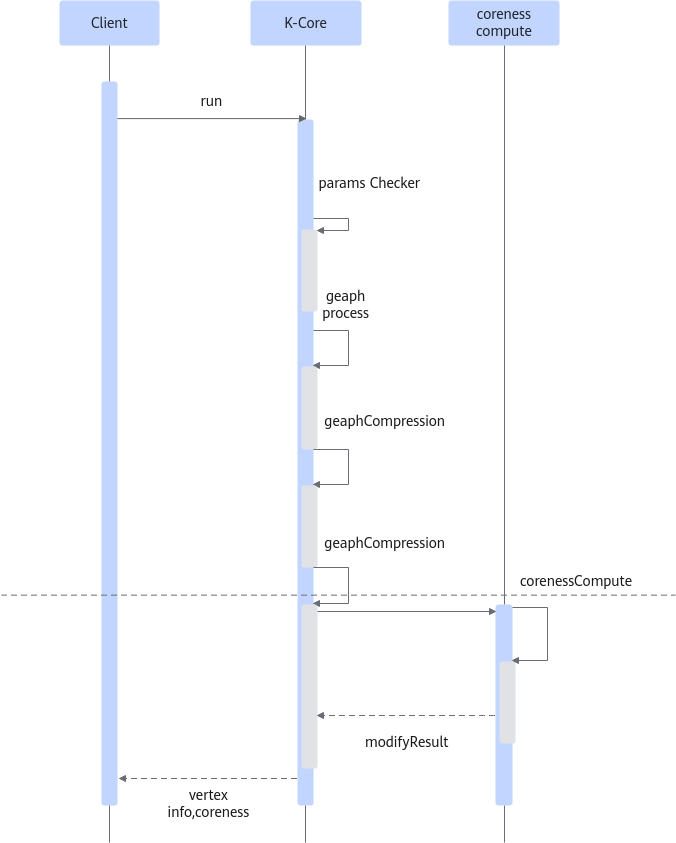
K-Core算法时序图如下图1所示。
- API描述
- 使用KCoreDecomposition样例:
val sc = new SparkContext(new SparkConf().setMaster("yarn").setAppName("KCore")) val inputGraphRaw = Array((1L, 2L), (3L, 2L), (3L, 1L), (4L, 5L)) val edegeList = sc.parallelize(inputGraphRaw) val res = KCoreDecomposition.run(edgeList).collectAsMap() - 样例结果:
Res = Map(1L -> 2, 2L -> 2, 3L -> 2, 4L -> 1, 5L ->1)