鲲鹏自动调优功能介绍
|
使用场景 |
应用启动方式 |
压测方式 |
使用说明 |
|
|---|---|---|---|---|
|
数据库 |
MySQL |
通过mysqld指定配置文件方式启动。 |
使用Sysbench压测。 |
支持生成简易调优模板,直接修改简易模板文件进行调优,各场景详细内容可参见3。 |
|
openGauss |
通过gs_ctl指定数据库文件夹方式启动。 |
使用BenchmarkSQL压测。 |
||
|
Vastbase |
通过vb_ctl指定数据库文件夹方式启动。 |
使用BenchmarkSQL压测。 |
||
|
RocksDB |
通过db_bench工具进行启动。 |
使用rocksdb_dbbench进行压测。 |
||
|
PostgreSQL |
通过pg_ctl指定数据目录启动。 |
使用BenchmarkSQL压测。 |
||
|
Redis |
通过redis-server指定数据目录启动。 |
使用自带的redis-benchmark压测。 |
||
|
大数据 |
Hive |
通过hive可执行文件启动。 |
使用tpcds进行压测。 |
|
|
Spark |
自动加载配置文件。
|
使用tpcds进行压测。 |
||
|
Flink |
自动加载配置文件。
|
使用HiBench压测。 |
||
|
Kafka |
通过kafka-server-start.sh指定配置文件方式启动。 |
使用自带的kafka-producer-perf-test.sh压测。 |
||
|
自定义 |
Custom |
- |
- |
支持生成自定义调优模板,直接修改自定义模板文件进行调优。
说明:
工具提供自定义调优模板,直接修改模板文件进行调优。详细内容可参考自定义模板修改参考。 |
前提条件
- 已参照安装工具安装鲲鹏自动调优工具。
- 使用压缩包安装工具时,请解压后切换至工具目录使用,采用./方式执行命令,例如./devkit kat -h。使用RPM包安装工具时,可直接执行命令,例如devkit kat -h。本章示例均为RPM包安装使用。
命令功能
基于不同场景的应用性能指标进行应用配置参数的自动寻优。
命令格式
1
|
devkit kat [-h | --help] TASK [ARGS] |

- 任务参数配置:参数名称、取值范围和设置方式等。
- 应用程序场景:应用、Benchmark(若存在)和性能指标等,其中必须保证应用和性能测试工具均可正常运行。
请根据实际业务场景和需要调优的参数,调整参数配置和应用程序场景。
使用示例
执行以下命令,查看自动调优支持的功能信息:
1
|
devkit kat -h |
返回信息如下:
1 2 3 4 5 6 7 8 9 10 |
Usage: devkit kat [-h | --help] TASK [ARGS] The most commonly used devkit kat sub tasks are: help Get help information train Run the auto tuner train task template Run the auto tuner template task use Run the auto tuner use task man Run the auto tuner man task See 'devkit kat TASK --help' for more information on a specific task. |
|
功能 |
说明 |
说明 |
|---|---|---|
|
help |
查看帮助信息。 |
- |
|
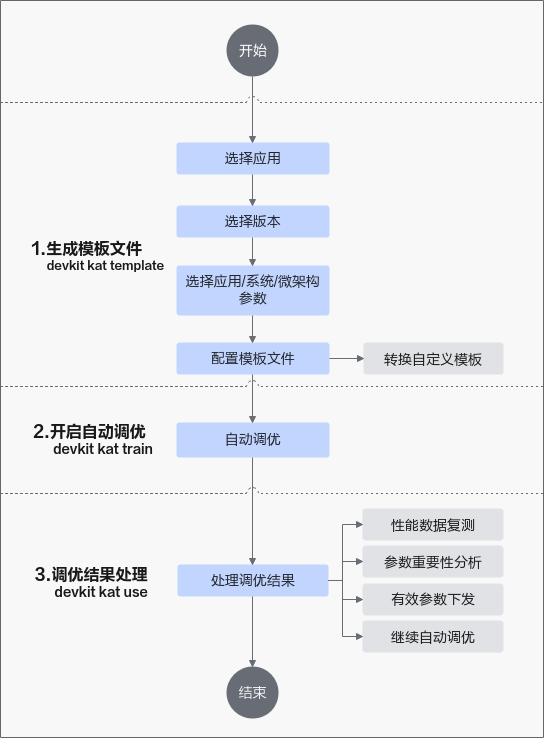
train |
开启自动调优。 |
开始自动调优,任务的参数配置根据业务场景指标自动调优。 |
|
template |
生成模板文件。 |
生成鲲鹏自动调优的参数空间和应用程序场景模板的配置。配置生成后可运行“devkit kat train -t task.yaml -p param.yaml”开始自动调优。 |
|
use |
运用调优结果。 |
运用自动调优后的报告结果,也可直接指定参数文件目录,在use功能交互界面进行调优。 |
|
man |
查看功能手册。 |
查看工具的功能手册,可查看所有命令的功能介绍以及使用示例。 |