CPU缓存
CPU读取数据,一般需要从内存中读取,然后放到寄存器中,接着才能进行计算操作。随着计算机的发展,内存的访问速度和寄存器的访问速度差距变得越来越大,程序在从内存读取数据这一个阶段有大量的开销,影响计算机整体性能。为了解决这个问题,人们便在内存和寄存器中间添加CPU缓存。因为寄存器从CPU缓存层读取数据的访问速度是优于从内存中直接读取的,通过添加CPU缓存的方法能有效提高计算机整体性能。目前CPU一般有三层缓存,分为L1,L2和L3。具体存储层次结构如CPU缓存所示。
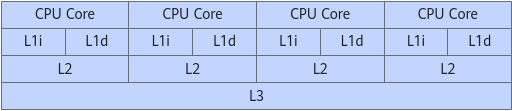
L1是最接近寄存器的CPU缓存层,也是L1-L3中访问速度最快的,但相对的容量也是最小的。此外,与L2和L3不同,L1缓存分为指令缓存和数据缓存,指令缓存是专门存放指令的,而数据缓存是专门存放数据的,两者不会混用,不存在指令存放到数据缓存中,也不存在数据存放在指令缓存中。这么设计是考虑到L1最接近寄存器,容量也是最小的。如果不做区分,很有可能读取上来一堆指令到L1,然后需要操作数据又读取数据到L1,把指令给替换掉,指令又需要去L2取,得不偿失。
L2缓存比L1缓存访问速度慢,但容量也比L1缓存大。L2缓存不区分指令缓存和数据缓存。这里需要注意,每一个CPU core都有自己独立的L1缓存和L2缓存。
L3缓存是三级CPU缓存中容量最大的,但也是访问速度最慢的。L3缓存与L1缓存和L2缓存不一样,由多个CPU core共享。
当CPU执行操作需要数据,会优先从L1中寻找,如果找不到,会依次去L2和L3读取。如果都没有读取到就会到内存中去读取,这种情况也被称为缓存不命中。
鲲鹏架构和x86架构服务器基本上都是采用L1-L3三层缓存。但每级缓存的大小和访问速度不完全一样。对于程序开发来说,尽量让数据可以在L1中访问到,能有效提高程序性能。良好的数组访问顺序,结构体数据成员对齐,结构体布局优化都是基于CPU缓存原理提高程序性能的有效方法。
良好的数组访问顺序
由于数组是连续的数据,在内存中也是连续存放的,如果访问数组也是按照数组在内存中的存放顺序,可以有效地提升缓存命中率,从而提升性能。以二维数组为例,同样遍历了数组,当二维数组B按列与数组A相加,此时列元素在Cache中非连续的。因为L1大小的限制,当在L1获取完某个元素并计算完后,紧接着的下一列的元素无法在L1中获取,那么下一次计算就需要先去L2,L3甚至内存去读取数据,性能相对较差。通过调整数组访问顺序,改为二维数组A与二维数组B的行元素相加,则可以从Cache中连续读取数据。重排前耗时544939μs,重排后235722μs。
按列读取:
for (int i = 0; i < ARRAYLEN; i++) {
for (int j = 0; j < ARRAYLEN; j++) {
arrayC[i][j] = arrayA[i][j] + arrayB[j][i];
}
}
改为按行读取:
for (int i = 0; i < ARRAYLEN; i++) {
for (int j = 0; j < ARRAYLEN; j++) {
arrayC[i][j] = arrayA[i][j] + arrayB[i][j];
}
}
结构体数据成员对齐
结构体数据成员对齐的原则是,第一个数据成员放到offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小的整数倍开始。具体看个例子。结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的整数倍,不足的要补齐。
struct Test1{
char a;
double b;
int c;
short d;
}Test1;
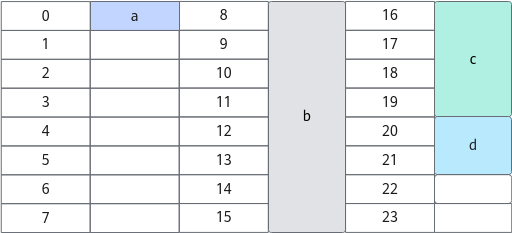
按照结构体数据成员对齐的原则,对于Test1来说,其在内存中的存储位置如图2所示,可以看出,整个结构体占的内存位置为0~23,但实际上1~7、22~23的内存位置是padding。
这时候有另一个结构体Test2,可以看到,Test1和Test2两个结构体实际上具有相关功能,但成员变量的顺序调整了一下。
struct Test2{
double b;
int c;
short d;
char a;
}Test2;
按照结构体数据成员对齐的原则,对于Test2来说,其在内存中的存储位置如图3所示,可以看出,整个结构体占的内存位置为0~15,实际上只有15的内存位置是padding。
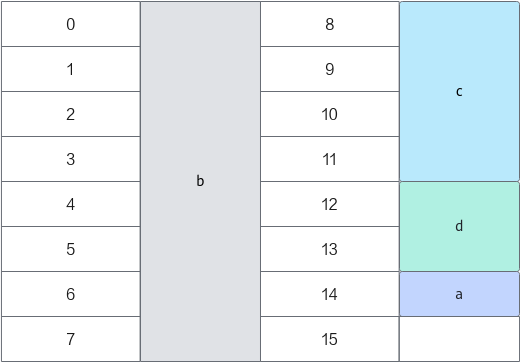
从上面分析可以看到,编程时实现相同功能的结构体,Test2比Test1节约了三分之一的内存空间,这能大大提高内存的使用率以及数据的紧凑性,更利于L1命中,有效提升了性能。
结构体内存布局设计
关于结构体布局,不同的编程布局可能会带来不同的效果。下面以结构体数组和数组结构体两种数据组织方式来介绍。如下是结构体数组定义。
结构体数组:
struct Array{
int x;
int y;
};
struct Array stArray[N];
此时每一组x和y的存储是连续的,在内存中的存储格式为:

数组结构体定义如下。
数组结构体:
struct Array{
int x[N];
int y[N];
};
struct Array stArray;
此时x和y是分开存储的,在内存中的存储格式为:

当业务场景主要针对x进行操作时,数组结构体相比结构体数组,x加载到内存和Cache中的数据是连续的,可以提高Cache Line的有效性和Cache的命中率,从而提高性能。因此在编程时,建议根据实际场景设计合适的结构体内存布局。