执行Spark UDF
当需要把UDF函数下推到OmniData算子下推服务时,需要部署UDF依赖包,以huawei-udf为例。
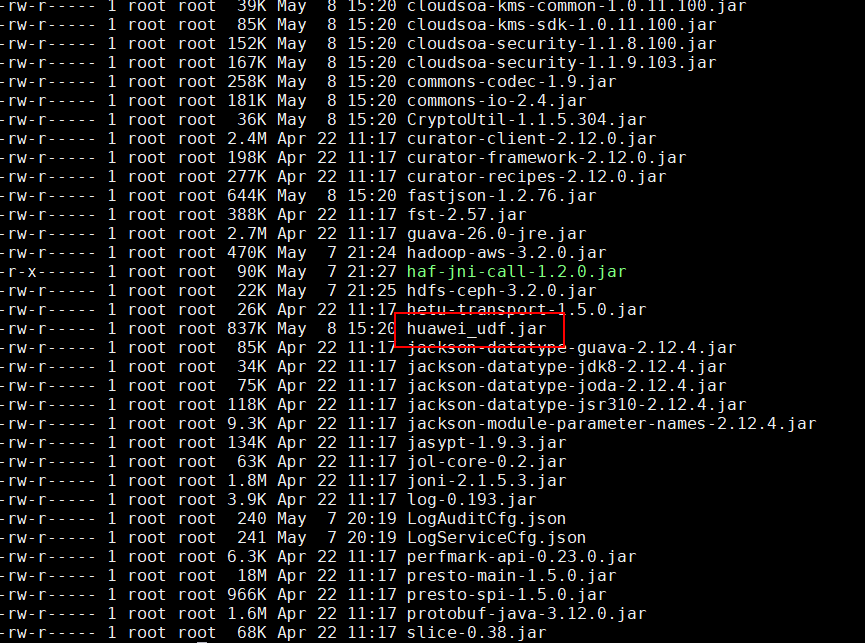
- 在本地“/opt/boostkit”目录下部署huawei_udf.jar。
- 运行UDF前需要将其注册到metastore,注册的方式有很多,本节以AdDecryptNew为例:
CREATE TEMPORARY FUNCTION AdDecryptNew AS "com.huawei.udf.AdDecryptNew";
- 运行Spark UDF算子下推。
/usr/local/spark/bin/spark-sql --driver-class-path '/opt/boostkit/*' --jars '/opt/boostkit/*' --conf 'spark.executor.extraClassPath=./*' --name udf_sqls/UDF_AdDecryptNew.sql --driver-memory 50G --driver-java-options -Dlog4j.configuration=file:../conf/log4j.properties --executor-memory 32G --num-executors 30 --executor-cores 18 --properties-file tpch_query.conf -f UDF_AdDecryptNew.sql;
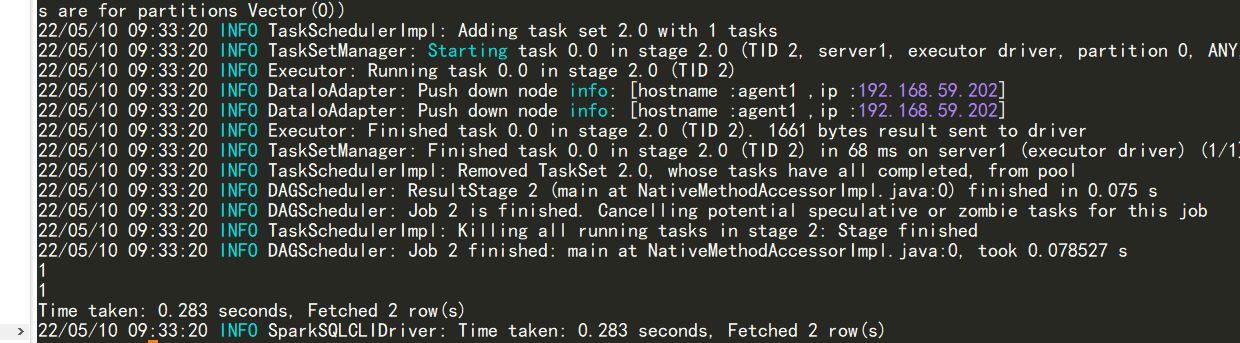
执行结果如下。