


RAG解决方案概述
RAG(Retrieval-Augmented Generation,检索增强生成)解决方案是一种结合检索和生成技术的模型,旨在通过引用知识库的信息来生成高质量、准确且具有可解释性的答案或内容。利用知识库进行信息检索,为LLM生成过程提供丰富的背景知识和上下文信息,从而提高生成结果的准确性和多样性。
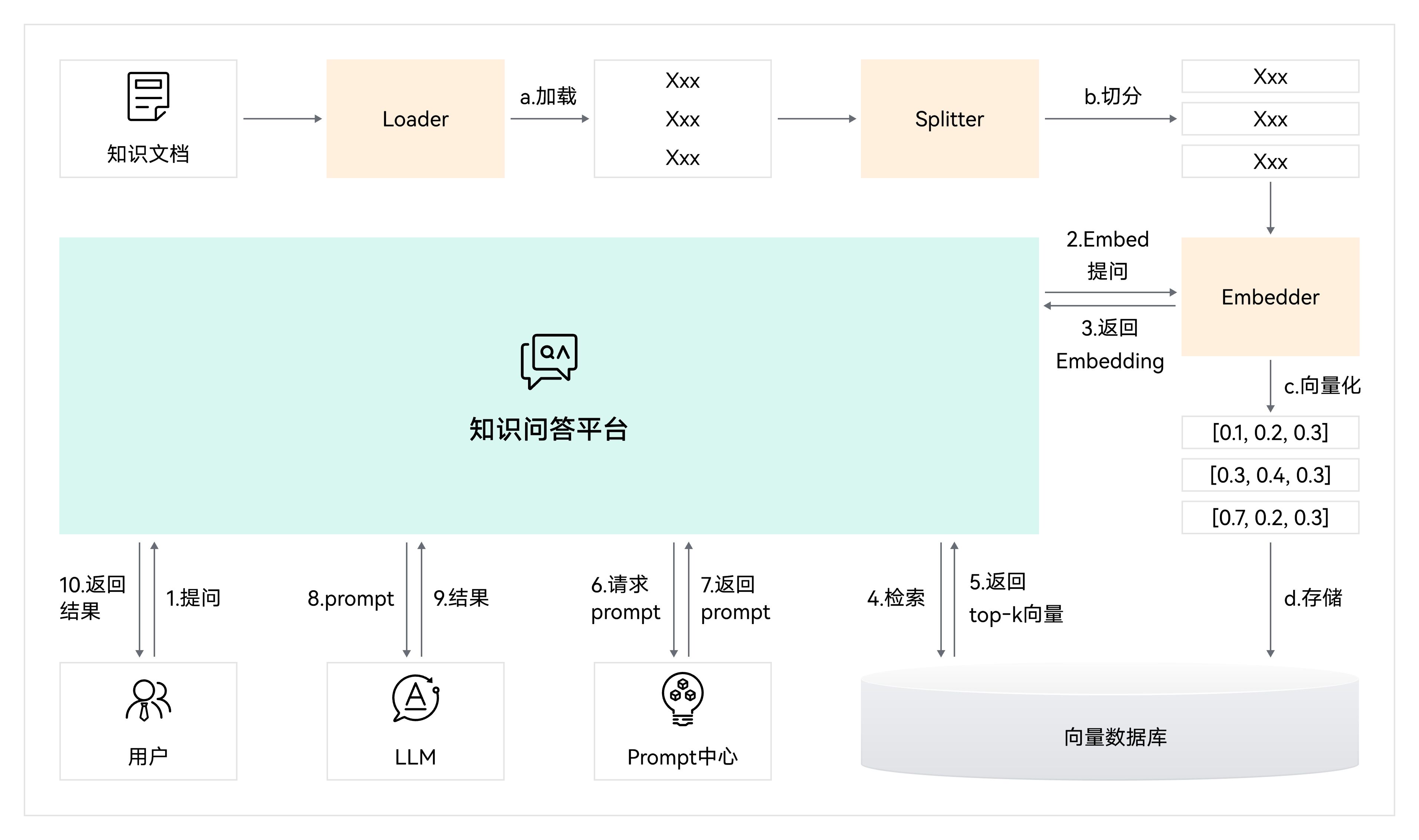
知识库构建流程(离线)
- 用户准备已有的知识文档,通过系统的Loader模块加载到RAG系统中。
- RAG调用Splitter分割模块对加载的知识文档进行切分,Splitter具备不同的切分算法,如固定大小分割,关键词分割等。
- 切分后的词通过Embedder模块进行向量化,转化为向量数据。
- 最后将向量数据存储到向量数据库中,从而完成本地知识库的构建。
- 用户在对话框中输入问题。
- 对输入的问题文本通过Embedding转换为向量数据并返回。
- 根据问题转换的向量数据在向量数据库中检索并返回相关数据信息。
- 向量检索返回的数据信息通过重排返回Top-K个相似度最高的结果。
- 将返回的Top-K个结果和用户提问一起整合为Prompt。
- 将Prompt输入到LLM大模型中,大模型根据提示词生成结果并返回。
关键技术
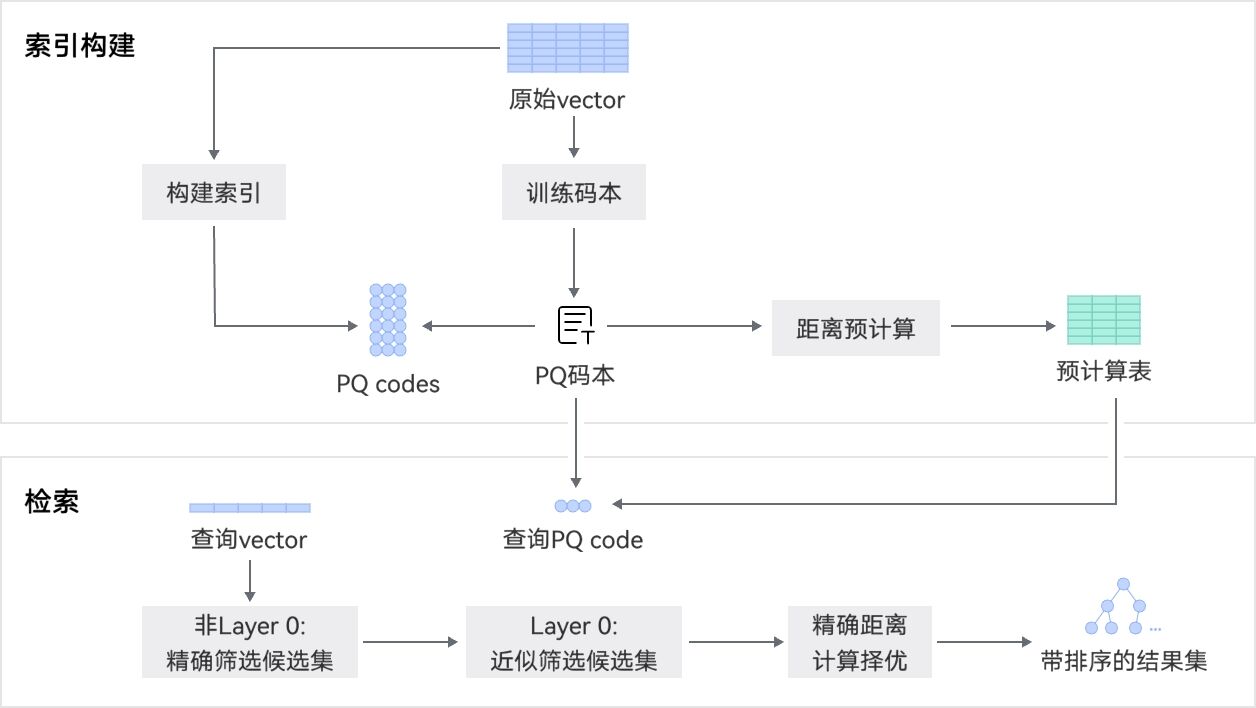
向量检索加速
价值优势
openGauss向量数据库在支持主流向量索引IVF-Flat/HNSW的基础上,通过与鲲鹏的深度软硬协同,基于BoostKit鲲鹏加速库、向量化指令加速,全面提升检索性能,领先业内主流向量数据库30%。
关键技术
支持基于鲲鹏BoostKit量化压缩算法,高效压缩高维向量,减少近似检索计算量,提升检索效率。通过鲲鹏NEON和SVE指令集对热点距离计算函数进行SIMD加速,充分利用鲲鹏多核算力,同时减少指令数量,降低访存次数,速度提升20%。

价值优势
高性能,响应/吐字效率高
BoostKit加速向量检索,openGauss向量数据库检索时延优于业内主流向量数据库30%
RAG独立部署,减少对推理资源占用,高并发下减少40%-80%推理时延影响,提升吐字效率
易部署,上线周期短
openGauss数据库“一库四用” 降低部署/运维难度
原生集成openEuler Intelligence AI流框架,部署效率是友商2倍
高安全,保护敏感数据
RAG安全网关,防护恶意数据库连接、SQL注入等行为
基于VirtCCA的机密安全虚机,防敏感数据窃取和篡改
易升级,扩容升级灵活
大模型和RAG模块分离部署,后期大模型随意组合升级,灵活性好
数据库独立部署,可随知识库增加而扩容,平滑扩展
最佳实践

%20rotate(90.000000)%20translate(-33.777778,%20-32.000000)%20'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
鲲鹏RAG实践教程
介绍鲲鹏RAG解决方案,包括方案部署指南,实践案例指导等
相关资源
应用场景

金融
金融信贷、智能营销客服等

医疗
病例总结、出院小结等

安平
笔录分析,法律助手等

数字政府
政务智能问答,智能办公等