服务器重启后某个OSD无法正常启动的解决方法
问题现象描述
环境配置:
硬件配置 |
鲲鹏服务器(25*2.5英寸硬盘EXP机箱,2*鲲鹏920处理器,32 Core@2.6GHz) 通用硬盘-2400GB-SAS 12Gb/s-10K rpm-256MB-2.5英寸(2.5英寸托架)*20 固态硬盘-1920GB-SATA 6Gb/s-读写混合型-SM883系列-2.5英寸(2.5英寸托架)*4 |
|---|---|
操作系统 |
CentOS 7.6 (Kerel 4.14) |
问题描述:服务器重启后osd.36无法正常启动。
关键过程、根本原因分析
- 查看 ceph-osd.36.log发现一直打印。
ERROR: unable to open OSD superblock on /var/lib/ceph/osd/ceph-36: (2) No such file or directory
- 说明该OSD在启动过程中无法加载到bcache,导致启动失败。
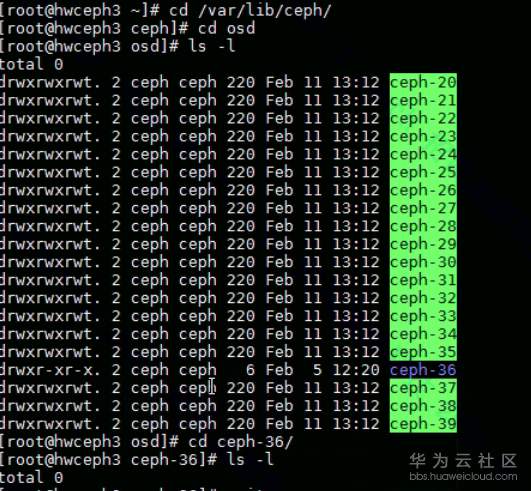
- 查找丢失bcache所在的服务器。假设当前环境1个SSD盘带5个HDD盘,那么当前服务器4块SDD盘和20块HDD盘,就会有40个bcache。
发现在 hwceph3 这台环境中少了2个。如下图。

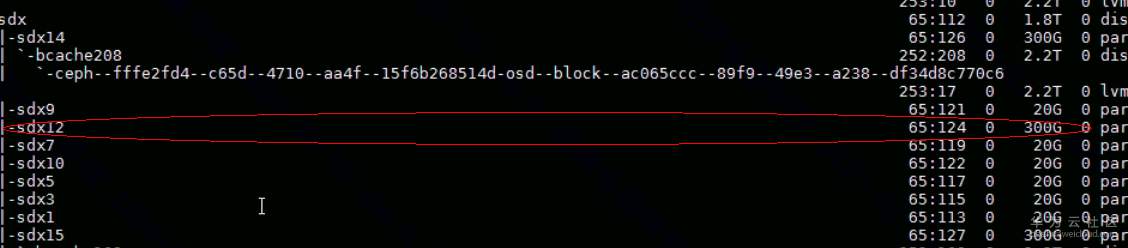
- 通过lsblk逐一排查丢失bcache的位置,发现SSD盘的sdx12和HDD盘的sdq1的bcache丢失,如下图:
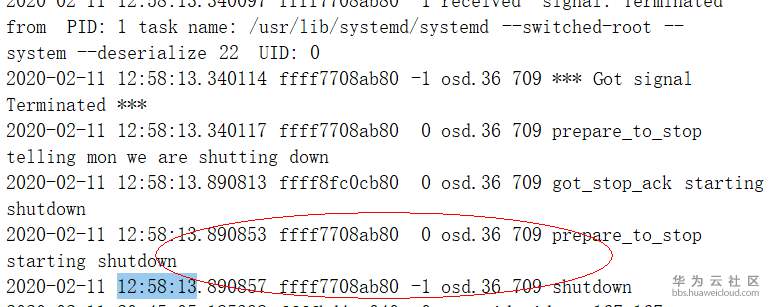
- 通过查看ceph-osd.36.log发现在2月11日12:58:13这个时间点有shutdown日志信息,如下图:
- 通过查看“/var/log/message”的日志信息发现在13:09:29这个时间点有系统启动的日志打印,说明这个时候有服务器重启的操作,触发了osd.36 shutdown的操作,如下图:
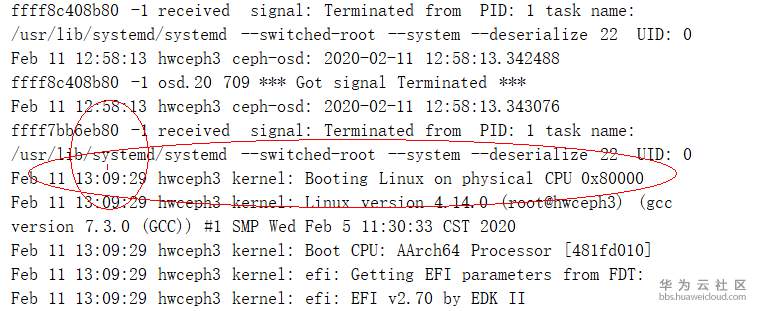
综上以上信息可以确认,osd.36在13:09:29这个时间点的系统启动过程中,由于关联的bcache丢失,无法加载bcache导致无法启动。
- 查看“/var/log/message”日志发现,在13:11:10 这个时间点,日志显示“journal entries 13614982-13614983 missing!”,表明bcache丢失。
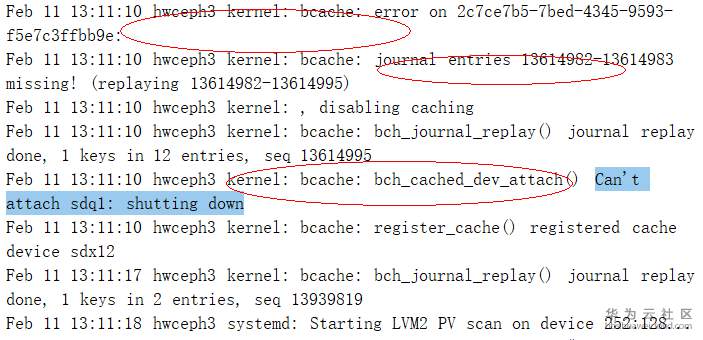
- 下载内核代码并结合日志信息可以发现,当机器重启后,journal buckets在恢复过程中需要恢复13614982-13614995这段日志信息。但13614982-13614983这段的日志丢失了,因此只恢复了12个 entries,所以系统会提示“journal entries 13614982-13614983 missing!”。当系统检测到数据不一致后,就把sdq1的bcache给shutdown了。
结论、解决方案及效果
在bch_journal_replay函数的日志信息中增加判断条件,开源代码如下:
git a/drivers/md/bcache/journal.c b/drivers/md/bcache/journal.c
