Failed to Restart OSDs in a Ceph Cluster
Problem Description
Item |
Information |
|---|---|
Source of the Problem |
Online maintenance |
Product |
Kunpeng BoostKit |
Sub-item |
SDS |
Service Scenario |
Debugging and running |
Component |
Other |
Output Time |
2019-10-28 |
Author |
Chen Xiaobo 00416232 |
Team |
Kunpeng BoostKit |
Review Result |
Review passed |
Review Date |
2019-11-05 |
Release Date |
2020-03-20 |
Keywords |
Failed to restart OSDs |
Symptom
- After a round of read/write performance test on a Ceph cluster, restart OSDs in the cluster and continue the read/write test. The test tool reports the following message:
java.lang.RuntimeException: Slave hd2-0 prematurely terminated. at Vdb.common.failure[common.java:335) at Vdb.SlaveStarter.startSlave(SlaveStarter.java:198) at Vdb.SlaveStarter.run(SlaveStarter.java:47)
The following figure shows the detailed information.

- Check the status of the Ceph cluster. Some OSDs are down, as shown in the following figure:
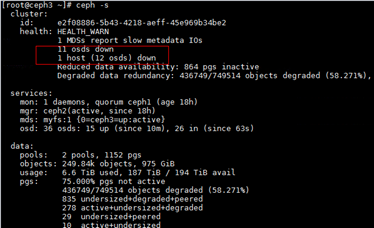
Key Process and Cause Analysis
The value of osd_memory_target is not the default value (4 GB) released officially.
Conclusion and Solution
- View Ceph logs. It is found that memory fails to be allocated to Ceph. An exception may occur when the OSDs attempt to obtain memory.
- Run the following command. The value of osd_memory_target is not the default value (4 GB) released officially.
ceph --admin-daemon /var/run/ceph/ceph-osd.0.asoc config show | grep memory

- Add osd_memory_target = 4294967296 to the ceph.conf file to limit the memory allocated to each OSD to 4 GB.
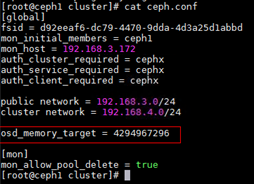
- Push the modified file to other nodes.
ceph-deploy --overwrite-conf admin ceph1 ceph2 ceph3 client1 client2 client3
- Restart the cluster.
systemctl restart ceph.target