Overview
Retrieval-Augmented Generation (RAG) is a technique that combines retrieval and generation. It aims to generate high-quality, accurate, and explainable answers or content by pulling information from knowledge bases. It provides LLMs with rich background knowledge and context information retrieved from knowledge bases, improving the accuracy and diversity of the generated results.

Knowledge base construction (offline)
- Users prepare knowledge documents and load them to the RAG system through the Loader module.
- RAG calls the Splitter module to split the loaded knowledge documents. The Splitter module supports various algorithms, such as fixed-size splitting and keyword-based splitting.
- The split words are vectorized by the Embedder module into vector data.
- The vector data is then stored in the vector database to form a local knowledge base.
- A user enters a question in the dialog box.
- The Embedder module converts the input question text into vector data through Embedding and returns the vector data.
- The platform retrieves the vector data in the vector database.
- The vector database reranks the retrieved information and returns the top K similar results.
- The platform integrates the returned top K results and user question into a prompt.
- The platform inputs the prompt into the LLM, and then the LLM generates results based on the prompt and returns the results.
Key Technologies
Vector Retrieval Acceleration
Benefits
openGauss supports mainstream vector indexes IVF-Flat and HNSW. Through hardware and software collaboration with Kunpeng, it leverages the Kunpeng BoostKit Library and vectorized instructions to improve retrieval performance by 30% compared with major vector databases in the industry.
Techniques
It supports high-dimensional vector compression based on Kunpeng BoostKit quantization and compression algorithms, reducing the calculation workload of approximate retrieval while improving retrieval efficiency. It uses Kunpeng NEON and SVE instruction sets to accelerate the hotspot distance calculation function using single instruction, multiple data (SIMD). This fully utilizes the multi-core computing power of Kunpeng and reduces the number of instructions and memory access times, increasing speeds by 20%.
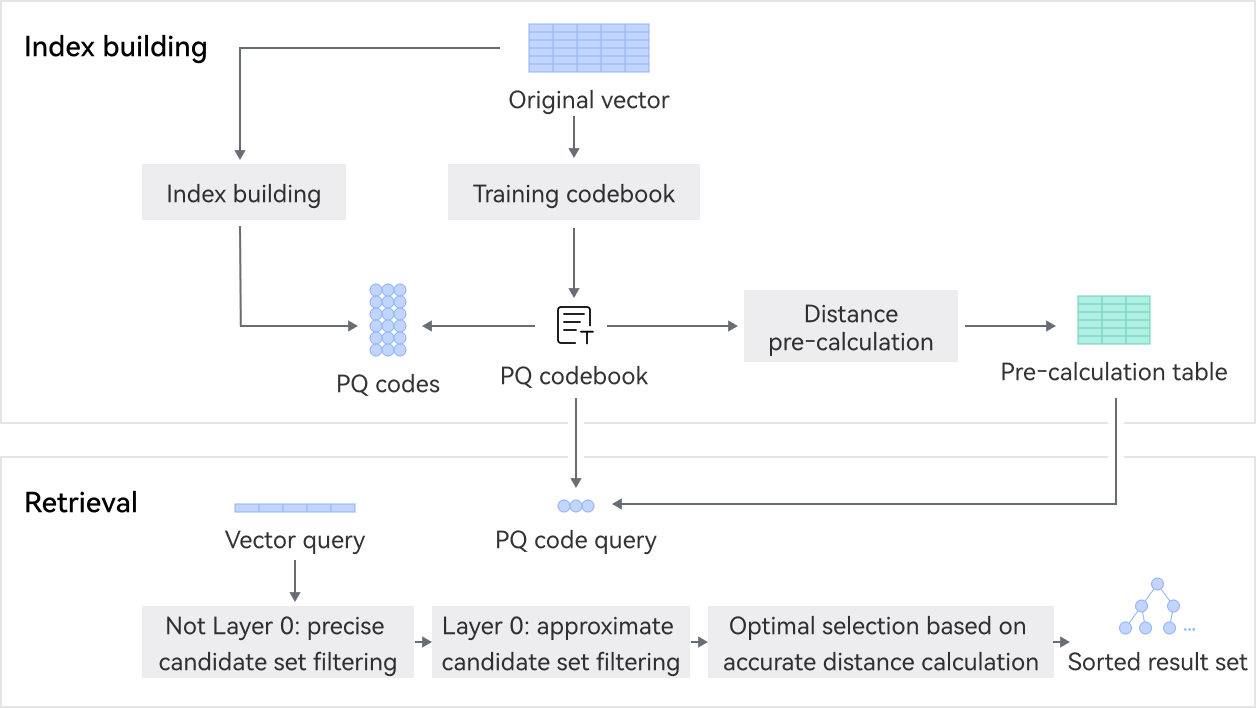

Benefits
High Performance for Efficient Response/Throughput
BoostKit accelerates vector retrieval. openGauss achieves approximately 30% lower retrieval latency compared to mainstream vector databases.
Independent RAG deployment reduces inference resource usage. In high-concurrency scenarios, this can reduce impact on inference latency by 40% to 80%, improving the throughput efficiency.
Easy Deployment for Fast Rollout
One openGauss database for four purposes simplifies deployment and O&M.
openGauss integrates the openEuler Intelligence AI stream framework, enabling twice the deployment efficiency of peers.
High Security for Sensitive Data Protection
RAG security gateways prevent malicious database connections and SQL injection.
Confidential VMs based on virtCCA prevent sensitive data from being stolen or tampered with.
Easy Upgrade for Flexible Capacity Expansion
The LLM and RAG modules are deployed separately. LLMs can be flexibly combined for upgrade.
The database is independently deployed and can be smoothly expanded as knowledge bases increase.
Application Scenarios

Finance
Financial credit, intelligent marketing customer service, etc.

Healthcare
Case summaries, discharge summaries, etc.

Public Safety
Record analysis, legal assistant, etc.

Digital Government
Intelligent question answering, intelligent office, etc.